8장, 분산 시스템의 골칫거리
결함과 부분장애
하드웨어 문제
- 하드웨어는 올바르게 동작하면 항상 같은 연산 결과를 냄
- 완전히 실패하거나 아니면 완전하게 동작함
부분 장애
- 비결정적인 장애
- 성공 여부를 알 수 없기 때문에 더욱 어려움
신뢰성 없는 네트워크
분산 시스템은 비공유 시스템을 의미한다. 즉, 네트워크로 연결된 다수의 장비
- 각 장비는 자신만의 메모리와 디스크를 가지고 있어, 다른 장비의 메모리나 디스크에 접근 할 수 없다.
- 네트워크가 유일한 통신 수단
비동기 패킷 네트워크
- 다른 노드로 메시지(패킷)을 보낼 수 있지만, 도착을 보장하지 않음
- 타임아웃으로 해결
네트워크 결함
네트워크 분단(분리): 네트워크 결함 때문에 다른 쪽과 차단이 되는 것
결함 감지
- 시스템은 결함이 있는 노드를 자동으로 감지 할 수 있어야 함
예시
1. 로드밸런스는 죽은 노드로 요청을 그만 보내야 함
2. 단일 리더 복제 분산 데이터베이스에서 리더 장애 시, 팔로워 중 하나가 리더로 승격
노드가 동작 중임을 알리는 방법
1. 목적지 포트에서 수신 대기하는 프로세스가 없다면 운영체제가 RST나 FIN 패킷을 응답으로 보내 TCP 연결을 닫음
> 노드가 요청을 처리하다 죽었다면 실제로 얼마나 데이터가 처리됐는 지 알 방법이 없음
2. 노드가 죽었지만 운영체제가 실행중이면 스크립트로 달느 노드에게 프로세스가 죽었다고 알림
3. 질의를 보내 하드웨어 수준의 링크 장애를 감지
4. 접속하려는 IP 주소에 도달할 수 없다고 라우터가 확신하면 ICMP 패킷으로 응답
- TCP가 패킷이 전달됐다는 확인 응답을 받아도 애플리케이션은 처리 전에 죽을 수 있음 -> 애플리케이션에게 직접 확인 응답을 받아야 함
- 일반적으로 아무 응답도 받지 못할것이라고 가정하여, 타임아웃을 기다림
타임아웃과 기약 없는 지연
타임아웃이 김: 노드가 죽었다고 선언되는 시간이 길어짐
↔ 짦음: 결함을 빨리 발견하지만 일시적인 느려짐에도 죽었다고 선언 할 수 있음
- 타임아웃 설정 방법
1. 모든 패킷은 전송 시간이 d보다 걸리지 않음
2. 장애가 나지 않은 노드는 항상 r 시간 내에 처리 보장
> 타임아웃 = 2d + r 시간 내에 응답을 보장
- 기약 없는 지연: 비동기네트워크는 패킷을 가능한 빨리 보내려고 하지만 패킷이 도착하는 데 걸리는 시간에 상한치가 없음
네트워크 혼잡과 큐 대기
네트워크 혼잡: 네트워크 링크가 붐비면 패킷은 슬롯을 얻을 수 있을 때까지 잠시 기다려야 함
- 들어오는 데이터가 많아 스위치 큐를 꽉 채우면 패킷이 유실됨
흐름제어(= 혼잡회피, 배압): 노드가 네트워크 링크나 수신 노드에 과부하를 가하지 않도록 자신의 송신율을 제한하는 것
> TCP에서 사용
> 타임아웃 안에 응답을 받지 않으면 패킷이 손실됐다고 간주하여 패킷을 재전송
고정된 타임아웃 설정 대신 지터(jitter)를 측정하고 관찰된 응답 시간 분포에 따라 타임아웃을 자동으로 조절하게 하는 것
동기 네트워크
- 데이터가 여러 라우터를 거치더라도 큐 대기 문제를 겪지 않음
- 네트워크가 다음 hop에 통화당 16비트의 공간이 할당 됐기 때문
- 제한 잇는 지연: 큐 대기가 없으므로 네트워크 종단 지연 시간 최대치 고정
신뢰성 없는 시계
-네트워크에 있는 개별 장비는 자신의 시계를 가지고 있는데, 해당 장치가 정확하지 않다.
-> 네트워크 시간 프로토콜로 서버 그룹에서 보고한 시간에 따라 컴퓨터 시계를 조정할 수 있도록 함
단조 시계 대 일 기준 시계
일 기준 시계
- 직관적으로 시계에 기대하는 일
- 현재 날짜와 시간을 반환
- NTP로 동기화하여 다른 장비의 타임스탬프와 동일한 의미를 지님
단조 시계
- 타임아웃이나 서비스 응답 시간 같은 지속시간을 재는 데 적합
- 두 값 사이의 차이로 두 번 확인 사이에 시간이 얼마나 흘렀는 지 확인
- 컴퓨터의 로컬 시계가 NTP서버보다 빠르거나 느리다는 것을 발견하면 단조 시계가 진행되는 진도수를 조정할 수 있음
시계 동기화와 정확도
- 일 기준 시계는 NTP 서버나 다른 외부 시간 출처에 맞춰 설정돼야 유용함
- NTP 데몬 설정이 잘못되거나 방화벽이 NTP 트래픽을 차단하면 드리프트에 따른 시계 오류가 커질 수 있음
- 시계가 잘못되었다는 것을 눈치채기 어려움 ▶ 모니터링을 통해 시계를 체크해야 함
최종 쓰기 승리(LWW, last write wins)
- "최근"의 정의는 로컬 일 기준 시계에 의존하며, 그 시계가 틀릴 수 있다는 것을 아는 것이 중요함
- 순차적인 쓰기가 빠른 시간 내에 연속으로 실행되는 것과 진짜 동시에 쓰기가 실행되는 것을 구별할 수 없음
- 두 노드가 독립적을 동일한 타임스탬프를 가진 쓰기 작업을 만들 수 있음
논리적 시계
- 진동하는 수정 대신 증가하는 카운터를 기반으로 하여 이벤트 순서화의 안전한 대안
시계 읽기의 신뢰 구간
어떤 시점에 읽는 것이 아닌, 신뢰 구간에 속하는 시간의 범위로 읽는 것
- 구글의 TrueTime API: 가장 이른 것과 가장 늦은 것을 가리키는 두 개의 값으로 실제 현재 시간이 그 구간 안 어디간에 있다는 것을 알 수 있음
저역 스냅숏용 동기화된 시계
- 스냅숏 격리: 작고 빠른 읽기 쓰기 트랜잭션과 크고 오래 실행되는 읽기 전용 트랜잭션 모두를 지원해야 하는 데이터베이스에서 아주 유용한 기능
구현
- 단조 증가하는 트랜잭션 ID 필요
- 스냅숏보다 나중에 쓰기가 실행됐다면 그 내용은 스냅숏 트랜잭션에게 보이지 않음
- 데이터베이스가 여러 데이터센터에 분산되어있는 경우, 전역 단조 증가 트랜잭션 ID 생성이 어려움
스패너
- 트루타입 API가 보고한 시계 신뢰 구간을 사용
- 가장 이른 타임 스탬프와 가장 늦은 타임 스탬프를 포함하는 두 개의 신뢰 구간이 있고, 두 구간이 겹치지 않는다면(Aearliest < Alastest < Bearliest < Blastest) B는 A보다 나중에 실행됨
- 트랜잭션 타임스탬프가 인과성 반영을 보장하기 위해 스패너는 읽기 쓰기 트랜잭션을 커밋하기 전에 의도적으로 신뢰 구간 길이만큼 기다림 ▶ 신뢰 구간이 겹치지 않음
프로세스 중단
파티션마다 리더가 하나씩 있는 데이터베이스가 있을 때, 노드가 여전히 리더인지, 안전하게 쓰기를 받아들일 수 있는 지 어떻게 알 수 있을까?
임차권(lease)
- 리더가 다른 노드들로부터 임차권을 얻음(타임아웃이 있는 잠금과 유사)
- 특정 시점에 오직 하나의 리더만 임차권을 얻을 수 있음 > 어떤 노드가 임차권을 획득하면 임차권이 만료될 때까지 자신이 얼마간 리더일 거라고 알 수 있음
- 노드가 계속 리더로 남아있으려면 임차권이 만료되기 전 주기적으로 갱신
if(lease.expiryTimeMillis - System.currentTimeMillis() < 10000){
...
}문제점
1. 동기화된 시계에 의존 -> 임차권 만료 시간이 다른 장비에서 설정됐는데, 로컬 시스템 시계와 비교
▶ 시계가 몇 초 이상으로 동기화가 깨지면 코드는 이상한 일 시작
2. 시간을 확인하는 시점과 요청이 처리되는 시점에서 예상치 못한 중단 발생
▶ 마지막으로 진행하기 전에 15초 동안 멈추면 요청 처리 시점에 다른 노드가 리더 역할을 넘겨받았을 수 있음
> GC, suspend 등 스레드가 멈추는 경우 존재
선점(preempt)
- 실행 중인 스레드를 어느 시점에 선점하고 얼마 시간이 흐른 후 재개 할 수 있음
- 단일 장비에서 다중 스레드 코드를 스레드 안전하게 만드는 것과 비슷
- 컨텍스트 스위치가 임의로 발생할 수 있고 병렬성이 발생할 수도 있으므로 타이밍에 대해 어떤 가정도 할 수 없음
- 뮤택스, 세마포어, 원자적 카운터, 잠금 없는 자료구조, 블로킹 큐 등 스레드를 안전하게 만들 수 있음
응답 시간 보장
- 중단의 원인 제거
- 소프트웨어가 응답해야하는 데드라인을 명시, 엄격한 실시간 시스템
실시간 운영체제(RTOS, real-time operating system)
- 소프트웨어 스택의 모든 수준에서 지원
- 프로세스가 명시도니 간격의 CPU 시간을 할당 받도록 보장
- 비실시간 환경에서 운영될 때 발생하는 중단과 시계 불안정으로부터 고통
가비지 컬렉션 영향 제한
- GC 중단을 노드가 잠시 동안 계획적으로 중단되는 것으로 간주하고 노드가 가비지 컬렉션을 하는 동안 클라이언트로부터의 요청을 다른 노드들이 처리하게 하는 것
- GC 중단이 필요하다고 경고하면 그 노드에 새로운 요청 보내기를 중단
이러한 분산시스템은 신뢰할 수 없는 네트워크를 통해 부분장애, 신뢰성없는 시계, 프로세스 중단에 시달린다
> 네트워크는 노드의 어떤 것도 확실하게 알지 못한다
시스템모델
분산 시스템에서 동작에 대해 과정 명시, 가정을 만족시키는 방식으로 증명
비대칭적 결함이 있는 네트워크
- 노드가 완벽하게 잘 동작하고 다른 노드가 보낸 요청을 받을 수 있더라도 다른 노드는 응답을 받을 수 없음
- 한쪽 연결이 끊긴 노드는 아무 일도 할 수 없음
긴 stop the world 가비지 컬렉션 중단 경험
- 노드의 모든 스레드는 GC에 선점되고 1분동안 멈춤
- 아무 요청도 처리되지 못하고 아무 응답도 전송되지 못함
- 다른 노드들이 노드가 죽었다고 선언하지만 GC 노드는 실제로 정상작동
▶ 분산 시스템은 한 노드에만 의존할 수 없음
정족수(quorum): 노드들 사이의 투표에 의존
- 특정 노드 하나에 대한 의존을 줄이기 위해 결정하려면 어려 노드로부터 최소 개수의 투표를 받아야 함
리더와 잠금
시스템이 오직 하나의 뭔가가 필요한 경우
1. 스플릿 브레인을 피하기 위해 오직 한 노드만 데이터베이스 파티션 리더가 될 수 있음
2. 특정한 자원이나 객체에 동시에 쓰거나 오염시키는 것을 방지하기 위해 오직 하나의 트랜잭션이나 클라이언트만 어떤 자원이나 객체 잠금을 획득할 수 있음
3. 사용자명으로 사용자를 유일하게 식별할 수 있어야 오직 한 명의 사용자만 특정한 사용자명으로 등록할 수 있음
- 어떤 노드가 "선택된 자"라고 생각하여도 정족수에게 투표를 얻지 못하면 처리할 수 없음
- 임차권을 가진 클라이언트가 오랫동안 멈춰있으면 임차권은 만료됨
펜싱 토큰
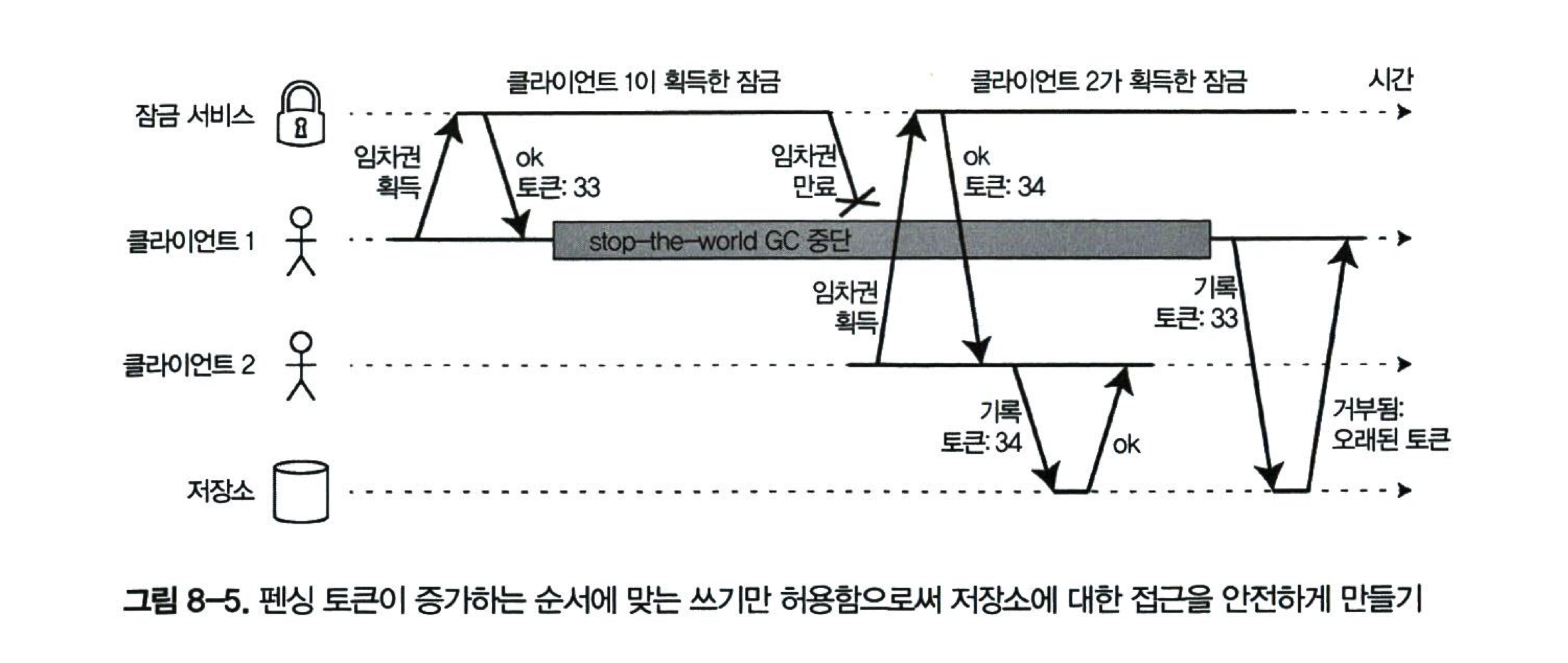
펜싱(fencing)
- 리소스에 대한 접근을 보호하기 위해 잠금이나 임차권을 쓸 때, 자신이 선택된 자라고 잘못 믿고 있는 노드가 나머지 시스템을 방해할 수 없도록 보장
펜싱 토큰
- 펜싱 토큰은 잠금이 승인될 때마다 증가하는 숫자
- 잠금 서버가 임차권을 승일할 때마다 펜싱 토큰을 반환한다고 가정
> 클라이언트가 쓰기 요청을 저장소 서비스로 보낼 때마다 자신의 현재 펜싱 토큰을 포함하도록 요구할 수 있음
- 오래된 토큰을 사용해서 쓰는 것을 거부
- 서버에서 토큰을 확인: 스스로 뜻하지 않게 폭력적인 클라이언트(다른 우선사항을 가진 것)로부터 보호
비잔틴 결함
어떤 노드가 실제로 받지 않은 특정 메시지를 받았다고 주장하는 경우, 신뢰할 수 없는 환경에 합의에 도달하는 문제를 비잔틴 장군 문제라고 함
- 펜싱 토큰은 부주의에 의한 오류(자신의 임차권이 만료됐다는 것을 아직 알차재지 못한 경우)에 빠진 노드를 감지하고 차단할 수 있음
- 노드가 고의로 시스템의 보장을 무너뜨리려 가짜 펜싱 토큰을 포함한 메시지를 보낼 수 있음 (정직X)
비잔틴 내결험상을 지님
- 일부 노드가 오작동하고 프로토콜을 준수하지 않거나 악의적인 공격자 네트워크를 방해하더라도 시스템이 계속 올바르게 동작함
약한 형태의 거짓말
1. 네트워크 패킷은 때때로 하드웨어 문제나 운영체제, 드라이버, 라우터 등의 버그때문에 오염
> TCP/UDP에 내장된 체크섬으로 검출이 되지 않은 경우도 있음
> 애플리케이션 수준 프로토콜에서 체크섬을 사용하여 보호
2. 공개적으로 접근 가능한 애플리케이션은 사용자 입력을 신중하게 살균해야 함
> 합당한 범위, 문자열 크기 제한 등
3. NTP 클라이언트는 여러 서버 주소를 설정할 수 있음. 동기화 시, 클라이언트는 모든 서버에 접속해 그들의 오차를 추정한 후 서버 중 다수가 어떤 시간 범위에 동의하는 지 확인
시스템 모델
타이밍 시스템 모델
1. 동기식 모델
- 네트워크 지연, 프로세스 중단, 시계 오차에 제한이 있음
- 네트워크 지연, 중단, 시계 드리프트가 결코 어떤 고정된 상한치를 초과하지 않을 것을 암
- 동기식 모델은 현실 시스템 대부분에서 현실적인 모델이 아님(기약없는 지연과 중단)
2. 부분 동기식 모델
- 대부분의 시간에 동기식 시스템처럼 동작하지만 때때로 네트워크 지연, 프로세스 중단, 시계 드리피트의 한계치르 초과
- 현실적인 모델
3. 비동기식 모델
- 타이밍에 대해 어떠한 가정도 할 수 없음
- 매우 제한적인 알고리즘을 가짐
노드용 시스템 모델
1. 죽으면 중단하는 결함
- 노드에 장애가 나는 방식이 죽는 것 하나 뿐
- 노드가 응답하기를 멈추면 이후 노드는 영원히 사용할 수 없음
2. 죽으면 복구하는 결함
- 어느 순간 죽어도 다시 응답하기 시작할 것이라고 가정
- 노드는 메모리에 있는 상태는 손실되지만 죽어도 데이터가 남아 있는 안정된 저장소가 있다고 가정
3. 비잔틴 결함
- 다른 노드를 속이거나 기만하는 것을 포함해 전적으로 무슨 일이든 할 수 있음
알고리즘 정확성
알고리즘의 속성
- 유일성: 펜싱 토큰 요청이 같은 값을 반환하지 않음
- 단조 일련번호: 요청 x가 토슨 tx를 요청 y가 토근 ty를 반환했고 y가 시작하기 전에 x가 완료됐다면 tx < ty를 만족
- 가용성: 펜싱 토큰을 요청하고 죽지 않은 노드는 결국에 응답을 받음
안정성과 활동성
안정성: 유일성, 단조 일련번호
- 나쁜 일은 일어나지 않음
활동성: 가용성
- 좋은 일은 결국 일어남
- 최종적 일관성, 결국에는
- 안정성 및 활동성 속성과 시스템 모델은 분산 시스템의 정확성을 따져보는 데 매우 유용
'IT > 책' 카테고리의 다른 글
| SI 개발자의 인프런 학습 목록 (0) | 2025.02.20 |
|---|---|
| [데이터설계] 3장, 저장소와 검색 - 트랜잭션 (0) | 2022.08.21 |
| [데이터설계] 3장, 저장소와 검색 (0) | 2022.08.18 |
| [데이터설계] 2장, 데이터 모델과 질의 언어 (0) | 2022.08.13 |
| [코딩인터뷰] 자료구조 - 배열과 문자열 해법 (0) | 2022.01.30 |


